You don't need Langchain; here's how to do Retrieval-Augmented Generation without it
In this article, we are going to build a Retrieval Augmented Generation pipeline from scratch using just Faiss, SBERT, and OpenAI for answer generation.

In this article, we will build a Retrieval-Augmented Generation(RAG) pipeline from scratch without using trendy libraries such as Langchain or Llamaindex.
A short intro about RAG.
Quoting from the Facebook (aka Meta) OG RAG paper.
Large pre-trained language models have been shown to store factual knowledge in their parameters, and achieve state-of-the-art results when fine-tuned on downstream NLP tasks. However, their ability to access and precisely manipulate knowledge is still limited, and hence on knowledge-intensive tasks, their performance lags behind task-specific architectures. Additionally, providing provenance for their decisions and updating their world knowledge remain open research problems.
Yeah, that's the exact problem RAG solves. In simple words, LLMs such as GPT lack factual consistency and lack up-to-date knowledge. To fix this, RAG is a technique that retrieves related documents to the user's question, combines them with LLM-base prompt, and sends them to LLMs like GPT to produce more factually accurate generation.
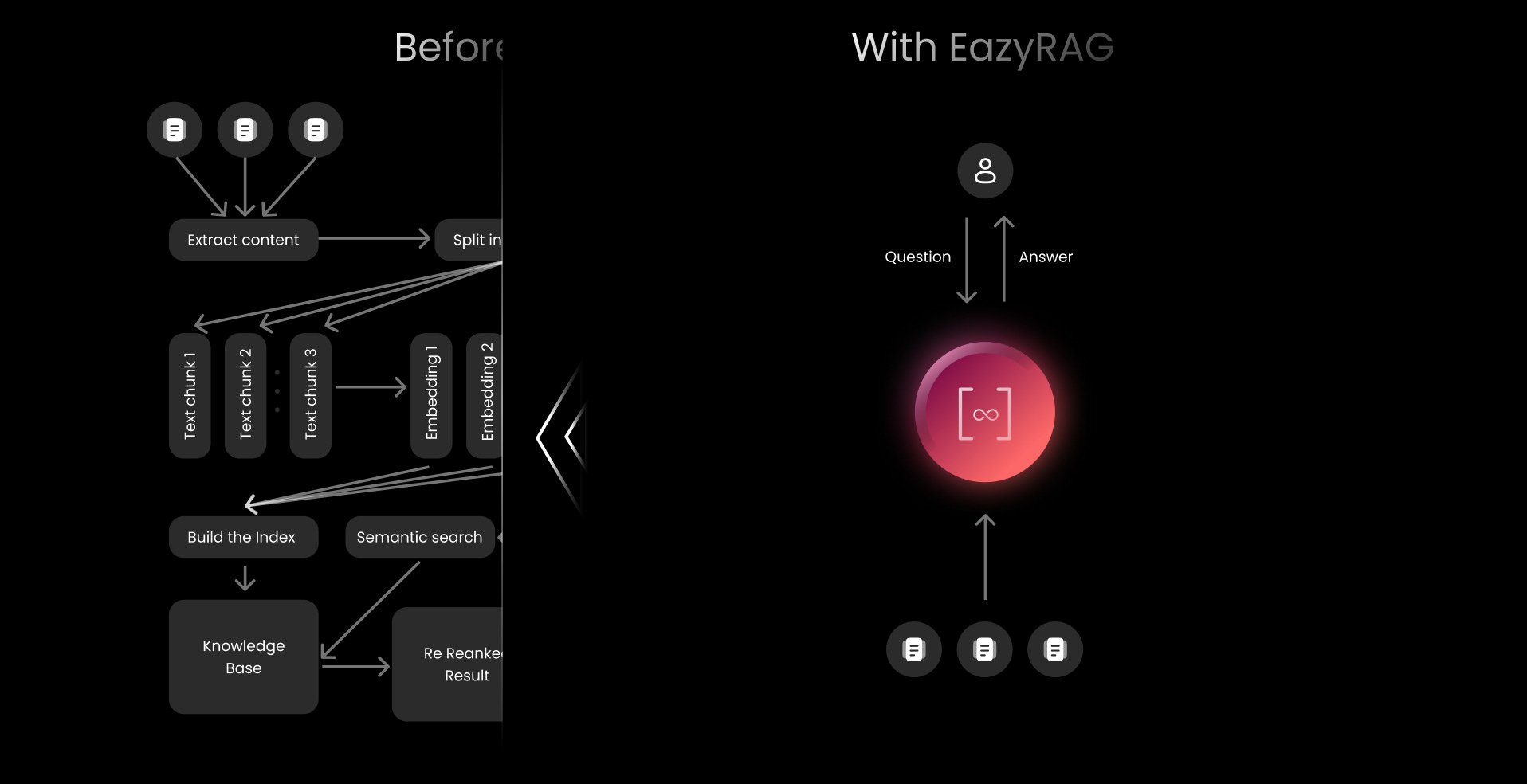
Here is the image I made to make visualization easier.

Let’s build
I will split the RAG pipeline into 5 parts:
Data preparation
Chunking
Vector store
Retrieval/Prompt preparation
Answer Generation
Shameless plug: If you don't want to go through the process above or customize chunking strategies using trendy libraries, please consider visiting eazyrag.com. We handle everything. Here is a demo I built in which I indexed the entire Bun Docs/Guides with just two simple network calls for indexing and answer generation.

Back to the article.
Data preparation
As we are planning to create a HackerNews (HN) support page, I have downloaded the relevant HTML pages, converted them to raw text, and saved them as JSON files.
data/
├── legal.json
├── newsfaq.json
├── newsguidelines.json
└── security.jsonJSON file looks something like this.
{
"content":"HTML converted into string...",
"url":"https://news.ycombinator.com/newsfaq.html"
}There is a reason I am adding a relevant URL to the file, when the LLM generates an answer, we can link back to the original URL used as context for citation.
Chunking
This is one of the important parts of the RAG pipeline. There are a whole lot of chunking strategies that deserve their own post, which I might write. But in short, here is how I decide this: when the answer is generated and cited with the citation number, I should be able to go back to the original sentence that has the answer on the HackerNews page by using text fragments.
So, we are going to split the content by sentence and save it as JSON with the URL key in every text fragment.
I removed the imports, don’t worry. I linked the final code at the bottom. Now let's only focus on the main parts of the code.
nlp = spacy.load("en_core_web_sm")
def process_file(file_path):
with open(file_path) as f:
data = json.load(f)
content = data['content']
url = data['url']
doc = nlp(content)
return [{'text': sent.text, 'url': url} for sent in doc.sents]
chunks = [chunk for file in os.listdir('data') for chunk in process_file(os.path.join('data', file))]
chunks = [{'id': i, **chunk} for i, chunk in enumerate(chunks)]
with open('chunks.json', 'w') as f:
json.dump(chunks, f)In the code above, I simply read all the files in the 'data' directory, iterated through the files, split them by sentence, assigned IDs to them (which we will use later), and saved them as 'chunks.json'.
Vector store
Now, we are going to convert all the chunks into embeddings. I am going to use the sbert all-mpnet-base-v2 model, but there are a lot of options available. Here is the leaderboard, and there is even a new state-of-the-art model (I’m still reading this paper).
sentences = [chunk['text'] for chunk in chunks]
model = SentenceTransformer('sentence-transformers/all-mpnet-base-v2')
embeddings = model.encode(sentences, show_progress_bar=True)
faiss_index = faiss.IndexFlatIP(model.get_sentence_embedding_dimension())
faiss_index.add(embeddings)In the code above, I converted all the texts into embeddings using the pre-trained embedding model and built the index using Faiss. If you have a large amount of data and are planning to use a bigger dimensional model, I'm pretty sure memory will be a problem.
If you are looking to quantize the faiss index size, you can manually quantize it, or you can use this nice tool which will produce the index at the specified size. It's a really cool tool and a huge time saver.
Retrieval/Prompt preparation
We are going to retrieve the relevant chunks to form the final prompt.
base_prompt = """You are an AI assistant. Your task is to understand the user question, and provide an answer using the provided contexts. Every answer you generate should have citations in this pattern "Answer [position].", for example: "Earth is round [1][2].," if it's relevant.
Your answers are correct, high-quality, and written by an domain expert. If the provided context does not contain the answer, simply state, "The provided context does not have the answer."
User question: {}
Contexts:
{}
"""k = 50
question = 'Why HackerNews is so popular?'
query_embedding = model.encode([question])
distances, indices = faiss_index.search(query_embedding, k)
context = '\n'.join([f'{i}. {sentences[index]}' for i, index in enumerate(indices[0])])
prompt = f'{base_prompt.format(question, context)}'In the code above, I retrieved all the relevant chunks, attached them to the base prompt, along with the user's question and context retrieved from the faiss_index, and formed the final prompt that we are going to send to GPT-3.5.
Answer Generation
Just send the prompt to OpenAI.
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo-16k-0613",
temperature=0,
messages=[
{"role": "system", "content": prompt},
]
)
print(response.choices[0].message.content)The response I got for “Why HackerNews is so popular?”
Hacker News is popular for several reasons:
1. Quality Content: Hacker News focuses on providing content that would be interesting to "good hackers" [8]. This means that the platform curates and promotes high-quality articles, discussions, and resources related to technology, startups, and hacking [8].
2. Community Engagement: Users are encouraged to vote and comment on content that they find interesting, rather than for self-promotion [12]. This fosters a sense of community engagement and encourages meaningful discussions.
3. Y Combinator Association: Hacker News is associated with Y Combinator, a well-known startup accelerator [11]. This association brings credibility and attracts entrepreneurs, investors, and tech enthusiasts to the platform.
4. Privacy and Security: Hacker News takes privacy and security seriously [2]. They have implemented measures to protect personal information and have a privacy policy in place [41]. This commitment to privacy and security helps build trust among users.
5. Diverse Topics: Hacker News covers a wide range of topics beyond just hacking and startups [4]. This diversity attracts users with different interests and backgrounds, making the platform more appealing and engaging.
6. Active Moderation: Hacker News has active moderation to prevent abuse and maintain the quality of discussions [22]. This helps create a positive and respectful environment for users. Overall, the combination of quality content, community engagement, Y Combinator association, privacy and security measures, diverse topics, and active moderation contribute to the popularity of Hacker News. [8][12][41][4][22][11].
Now you can parse the citations and find the relevant chunks. I am skipping this since that’s not the goal of this article.
Conclusion
I hope you now have a good understanding of the RAG pipeline. Here is the final code.
Now, the above process may look simple, but a lot of effort needs to be done for perfect retrieval and precise context generation. EazyRAG, the tool we are building, tackles this. We have incorporated a lot of different strategies to form a good context, which increases the quality of the answer.
Visit: https://eazyrag.com